
[ad_1]
我是自负盈亏的创业公司老板。因此,在说服财务总监花掉我们来之不易的自举资金之前,我想尽我所能。我也是一位具有数据和计算机科学背景的分析师,所以无论如何定义都有点怪胎。
我尝试着戴上SEO分析师的头衔,就是寻找大量免费数据来源,并将其整理成有见地的东西。为什么?因为将客户的建议基于猜想没有任何价值。最好将高质量的数据与良好的分析结合起来,以帮助我们的客户更好地了解对他们而言重要的是什么。
在本文中,我将告诉您如何开始使用一些免费资源,并说明如何组合独特的分析方法,这些方法可以为您的博客文章提供有用的见解(如果您是作家,则是代理机构,如果您是SEO,或者您的网站(如果您是自己进行SEO的客户或所有者)。
我要使用的方案是,我想分析一些SEO属性(例如,反向链接,Page Authority等),并查看它们对Google排名的影响。我想回答以下问题:“反向链接真的对进入SERP的第1页有效吗?”和“我真的需要在前10个结果中获得哪种页面权威评分?”为此,我需要结合起来来自许多Google搜索的数据,其中包含我要衡量的具有SEO属性的每个结果的数据。
让我们开始并研究如何结合以下任务以实现此目标,这些任务均可免费设置:
- 使用Google自定义搜索引擎查询
- 使用免费的Moz API帐户
- 使用PHP和MySQL收集数据
- 使用SQL和R分析数据
使用Google自定义搜索引擎查询
我们首先需要查询Google并存储一些结果。为了保持Google服务条款的正确性,我们不会直接抓取Google.com,而是会使用 Google的自定义搜索 特征。 Google的自定义搜索的主要目的是让网站所有者在其网站上提供类似Google的搜索小部件。但是,还有一个 休息 基于 谷歌搜索API 这是免费的,可让您查询Google并检索流行的结果 JSON格式。有 配额限制 但是可以对其进行配置和扩展,以提供良好的数据样本进行处理。
什么时候 正确配置 要搜索整个网络,您可以将查询发送到您的自定义搜索引擎(在我们的示例中是使用PHP),并将其视为Google响应,尽管有一些注意事项。使用自定义搜索引擎的主要限制是:(i)它不使用某些Google Web搜索功能(例如个性化结果);以及(ii)如果您包含十个以上的网站,则可能包含Google索引的一部分结果。
尽管有这些限制,但仍有许多 搜索选项 可以传递给自定义搜索引擎以代理您可能期望Google.com返回的内容。在我们的场景中,我们在拨打电话时传递了以下内容:
https://www.googleapis.com/customsearch/v1?key=
1个
哪里:
- https://www.googleapis.com/customsearch/v1 –是Google自定义搜索API的网址
- 键=
– 你的 Google Developer API 键 - userIp =
–进行呼叫的本地计算机的IP地址 - cx =
– 你的 Google自定义搜索引擎 ID - q = iPhone + X – Google查询字符串(“ +”代替“”)
- cr = countryUS-国家/地区限制(摘自Goolge's 国家/地区名称 清单)
- start = 1 –要返回的第一个结果的索引-例如SERP页面1。连续调用将使其递增以得到2-5页。
Google说过 Google自定义搜索引擎与Google .com不同,但是在有限的产品测试中比较两者之间的结果时,我对相似之处感到鼓舞,因此继续进行分析。也就是说,请记住,以下数据和结果来自Google自定义搜索(使用“整个网络”查询),而不是Google.com。
使用免费的Moz API帐户
Moz提供了 应用程序接口 (API)。要使用它,您需要注册一个 Mozscape API密钥,它是免费的,但每月限制为2500行,每十秒钟一次查询。当前 付费计划 给您增加的配额,起价为每月250美元。具有免费的帐户和API密钥,然后您可以查询 链接API 并分析以下内容 指标:
|
Moz数据字段 |
Moz API代码 |
描述 |
|---|---|---|
|
ueid |
32 |
外部数量 公平 链接到URL |
|
uid |
2048 |
到URL的链接数(外部链接,外部链接,是否等于或不等于) |
|
umrp ** |
16384 |
网址的MozRank,以10分标准化 |
|
umrr ** |
16384 |
网址的MozRank(原始分数) |
|
FMRP ** |
32768 |
URL子域的MozRank(归一化10分) |
|
fmrr ** |
32768 |
URL子域的MozRank(原始分数) |
|
我们 |
536870912 |
为此URL记录的HTTP状态代码(如果有) |
|
乌帕 |
34359738368 |
标准化的100分得分,表示页面在搜索引擎结果中排名良好的可能性 |
|
pda |
68719476736 |
归一化的100分得分代表域在搜索引擎结果中排名良好的可能性 |
注意:由于捕获了此分析,Moz记录表明它们已弃用这些字段。但是,在对此进行测试(15-06-2019)中,这些字段仍然存在。
在调用Links API之前,将Moz API代码添加在一起,如下所示:
www.apple.com%2F?Cols = 103616137253&AccessID = MOZ_ACCESS_ID&
过期= 1560586149&Signature =
哪里:
- http://lsapi.seomoz.com/linkscape/url-metrics/“ class =” redactor-autoparser-object“> http://lsapi.seomoz.com/linksc … – Moz API的URL
- http%3A%2F%2Fwww.apple.com%2F –我们要获取数据的编码URL
- Cols = 103616137253 –上表中的Moz API代码总和
- AccessID = MOZ_ACCESS_ID – Moz访问ID的编码版本(可在您的API帐户中找到)
- Expires = 1560586149 –查询超时-设置为未来几分钟
- 签名=
– Moz访问ID的编码版本(可在您的API帐户中找到)
Moz将返回类似以下JSON的内容:
数组
(
(ut)=>苹果
(uu)=> www.apple.com/
(ueid)=> 13078035
(uid)=> 14632963
(uu)=> www.apple.com/
(ueid)=> 13078035
(uid)=> 14632963
(umrp)=> 9
(umrr)=> 0.8999999762
(fmrp)=> 2.602215052
(fmrr)=> 0.2602215111
(我们)=> 200
(upa)=> 90
(pda)=> 100
)
有关使用PHP,Perl,Python,Ruby和Javascript查询Moz的一个很好的起点,请参阅此 Github上的存储库。我选择使用PHP。
使用PHP和MySQL收集数据
现在,我们有了Google自定义搜索引擎和Moz API,几乎可以捕获数据了。 Google和Moz通过JSON格式响应请求,因此许多流行的编程语言都可以查询。除了我选择的语言PHP外,我还将Google和Moz的结果都写到了数据库中,然后选择了 MySQL社区版 为了这。也可以使用其他数据库,例如Postgres,Oracle,Microsoft SQL Server等。这样做可以使用SQL(结构化查询语言)以及其他语言(例如R,我将在以后进行介绍)来实现数据的持久性和即席分析。在创建用于保存Google搜索结果的数据库表(具有用于排名,URL等的字段)和用于保存Moz数据字段(ueid,upa,uda等)的表之后,我们就可以设计数据收集计划了。
Google提供了一个 慷慨的配额 使用自定义搜索引擎(每天使用相同的Google开发者控制台密钥最多可查询1亿个查询),但是Moz免费API的数量限制为2500。尽管对于Moz来说,根据计划和方案的不同,付费的选择权每月可提供12万至4000万行,费用范围为每月$ 250- $ 10,000。因此,在我探索免费选项的同时,我设计了代码,以便在2页的SERP(每页10个结果)中收集125个Google查询,使我能够保持在2500行的Moz配额之内。至于哪些搜索可以触发Google,有很多资源可供使用。我选择使用 蒙多沃 因为它们提供了许多类别的列表,每个列表最多500个单词,对于实验来说足够了。
我还引入了一些PHP帮助程序类以及我自己的数据库I / O和HTTP代码。
总之,使用的主要PHP构建块和源是:
- Google自定义搜索引擎– 阿什·基斯瓦尼(Ash Kiswany) 用写了一篇很棒的文章 雅各布·福格的 Google自定义搜索的PHP接口;
- Mozscape API –如前所述, PHP实现 在Github上访问Moz是一个很好的起点;
- 网站搜寻器和HTTP –在 紫色工具,我们有自己的搜寻器 PurpleToolzBot 使用 卷曲 对于HTTP和这个 简单的HTML DOM解析器;
- 数据库I / O – PHP对MySQL具有出色的支持,我将它们包装成类 教程。
要注意的一个因素是 两次Moz API调用之间的间隔为10秒。这是为了防止免费API用户过载Moz。为了用软件处理此问题,我编写了一个“查询调节器”,该查询阻止了在一个时间范围内连续调用之间对Moz API的访问。但是,尽管运行良好,这意味着连续拨打Moz 2500次仅需不到7个小时即可完成。
使用SQL和R分析数据
收集数据。现在,乐趣开始了!
现在该看看我们所拥有的。有时称为 数据争吵。我使用一种称为的免费统计编程语言 [R 以及称为的开发环境(编辑器) R工作室。还有其他语言,例如 斯塔塔 以及更多的图形数据科学工具,例如 画面,但是这些费用和Purple Toolz的财务主管不是一个可以克服的人!
我使用R已经有很多年了,因为它是开源的,并且它具有许多第三方库,使其非常通用并且适合此类工作。
让我们卷起袖子。
现在,我有几个数据库表,其中包含我在SERPS的2页上的125个搜索词查询的结果(即,每个搜索词有20个排名的URL)。两个数据库表保存Google结果,另一个表保存Moz数据结果。要访问这些文件,我们需要做一个数据库INNER JOIN,我们可以通过使用 RMySQL的 通过在R的控制台中键入“ install.packages('RMySQL')”,并在我们的R脚本顶部包含“ library(RMySQL)”行来加载。
然后,我们可以执行以下操作来连接并将数据获取到名为“ theResults”的R数据帧变量中。
库(RMySQL)
#INNER JOIN这两个表
查询<-“
选择A。*,B。*,C. *
从
(
选择
cseq_search_id
从cse_query
)A-自定义搜索查询
内部联接
(
选择
cser_cseq_id,
cser_rank,
cser_url
来自cse_results
)B-自定义搜索结果
开启A.cseq_search_id = B.cser_cseq_id
内部联接
(
选择 *
从莫兹
)C-Moz数据字段
开启B.cser_url = C.moz_url
;
”
#(1)连接数据库
#用您的数据库用户名替换USER_NAME
#用您的数据库密码替换PASSWORD
#将MY_DB替换为您的数据库名称
theConn <-dbConnect(dbDriver(“ MySQL”),用户=“ USER_NAME”,密码=“ PASSWORD”,dbname =“ MY_DB”)
#(2)查询数据库并保存结果
结果<-dbGetQuery(theConn,theQuery)
#(3)断开与数据库的连接
dbDisconnect(theConn)
注意:我有两个表来保存Google自定义搜索引擎数据。一种保存Google查询中的数据(cse_query),另一种保存结果(cse_results)。
现在,我们可以使用R的全部统计功能来开始争论。
让我们从一些总结开始,以便对数据有所了解。我对每个字段执行的过程基本相同,因此,让我们举例说明并使用Moz的“ UEID”字段(外部 公平 网址链接)。通过在R中键入以下内容,我可以得到:
>摘要(theResults $ moz_ueid)
最小第一区中位数第三区最高
0 1 20 14709 182 2755274
>分位数(theResults $ moz_ueid,概率= c(1,5,10,25,50,75,80,90,95,99,100)/ 100)
1%5%10%25%50%75%80%90%95%99%100%
0.0 0.0 0.0 1.0 20.0 182.0 337.2 1715.2 7873.4 412283.4 2755274.0
观察这一点,您会发现数据由于中位数与均值的关系而偏斜(很大),而中位数与均值之间的关系被较高四分位数范围内的值(超过观测值的75%的值)拉动。但是,我们可以将其绘制为 R中的盒子和晶须图 其中每个X值都是从Google定制搜索排名1-20开始按等级排列的UEID分布。
请注意,我们在y轴上使用了对数刻度,以便我们可以显示变化范围很大的所有值!
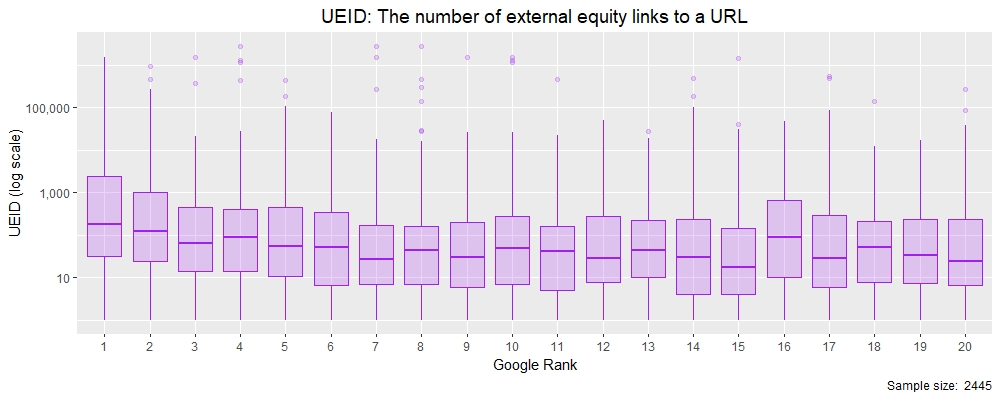 Google排名在Moz UEID R中的盒须图(注:对数刻度)
Google排名在Moz UEID R中的盒须图(注:对数刻度)
箱形图和晶须图很棒,因为它们在其中显示了大量信息(请参见R中的geom_boxplot函数)。紫色方框区域表示四分位间距(IQR),它是观测值的25%到75%之间的值。每个“框”中的水平线代表中间值(订购时位于中间),而从框延伸的线(称为“晶须”)代表1.5倍IQR。晶须外的点称为“离群值”,它显示每个等级的观察值集的范围。尽管有对数刻度,但我们可以看到中值从排名10上升到排名1明显,表明股权链接的数量可能是Google的排名因素。让我们进一步探讨 密度图。
密度图非常类似于分布(直方图),但显示的是平滑线而不是条形图。与直方图非常相似,密度图的峰值显示了数据值的集中位置,可以在比较两个分布时提供帮助。在下面的密度图中,我将数据分为两类:(i)排名1-10的SERP第1页上显示的结果为粉红色;以及(ii)在SERP第2页上显示的结果为蓝色。我还绘制了两种分布的中位数,以帮助说明Page 1和Page 2之间的结果差异。
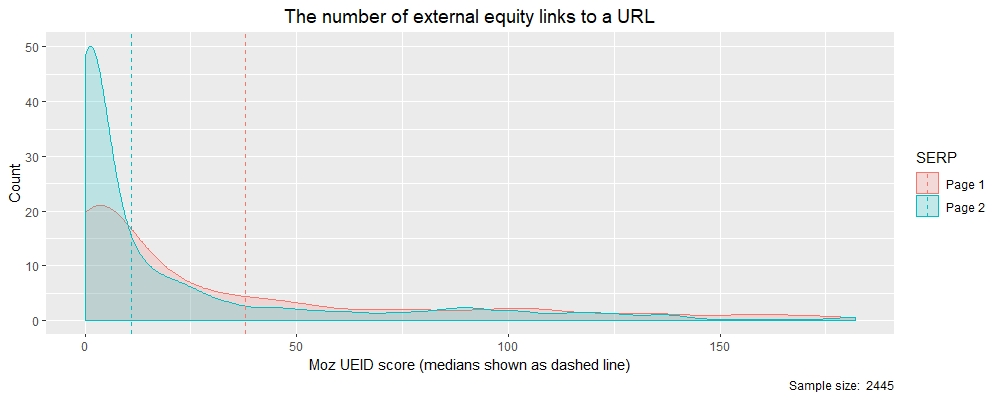
从这两个密度图得出的结论是,第1页SERP结果比第2页结果具有更多的外部股权反向链接(UEID)。您还可以在下面看到这两个类别的中值,清楚地显示了第1页(38)的值远大于第2页(11)的值。因此,我们现在有一些数字可用于反向链接的SEO策略。
#根据结果(cser_rank)所在的SERP页面在R中创建一个因子
>结果$ rankBin <- paste("Page", ceiling(theResults$cser_rank / 10))
> theResults $ rankBin <- factor(theResults$rankBin)
# Now report the medians by SERP page by calling ‘tapply’
> tapply(theResults $ moz_ueid,theResults $ rankBin,中位数)
第1页第2页
38 11
由此,我们可以推断出股权反向链接(UEID)很重要,如果我根据此数据为客户提供建议,我想说他们应该寻求38个以上基于股权的反向链接,以帮助他们进入SERP的第1页。当然,这是一个有限的样本,需要更多的研究,需要考虑更大的样本和其他排名因素,但是您可以理解。
现在,让我们研究另一个比UEID范围更小的指标,然后看看Moz的UPA指标,这是页面在搜索引擎结果中排名良好的可能性。
>摘要(theResults $ moz_upa)
最小第一区中位数第三区最高
1.00 33.00 41.00 41.22 50.00 81.00
>分位数(theResults $ moz_upa,概率= c(1、5、10、25、50、75、80、90、95、99、100)/ 100)
1%5%10%25%50%75%80%90%95%99%100%
12 20 25 33 41 50 53 58 62 75 81
UPA是提供给URL的数字,范围为0-100。数据的表现比以前的UEID无界变量的均值和中位数靠得很近,从而表现出更“正态”的分布,正如我们通过在R中绘制直方图看到的那样。
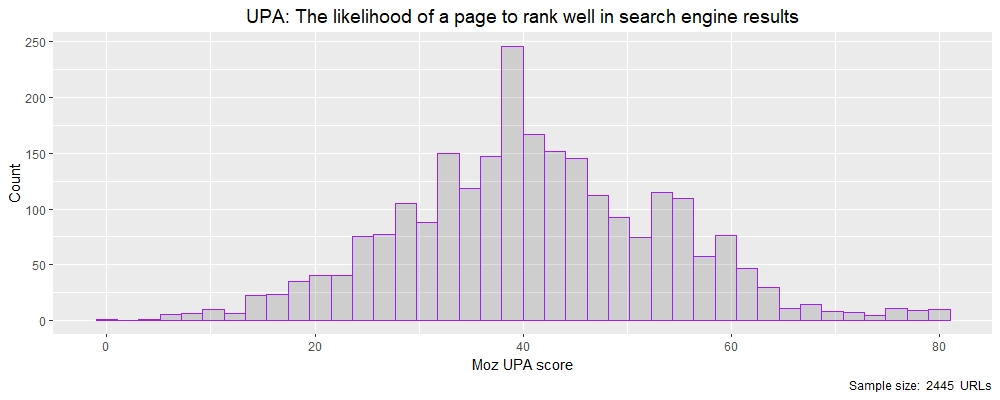 莫兹的UPA得分的直方图
莫兹的UPA得分的直方图
我们将像以前一样执行第1页:第2页的分裂和密度图,并在将UPA数据分为两组时查看UPA分数分布。
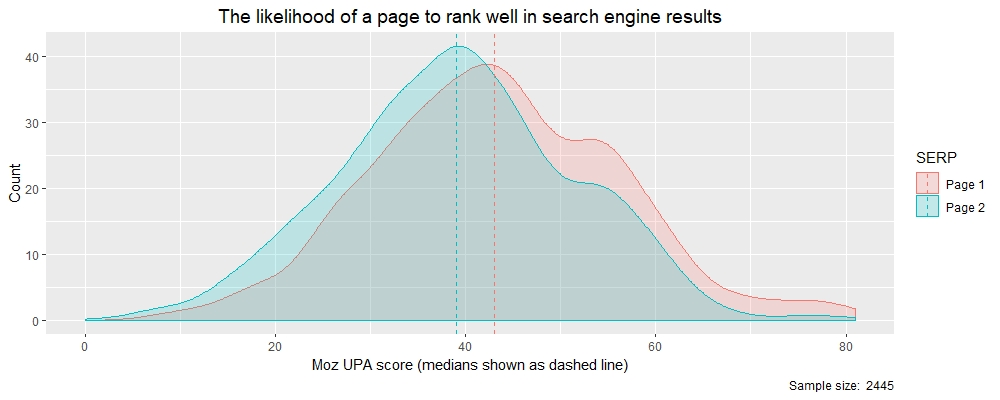 #调用“ tapply”按SERP页面报告中位数
#调用“ tapply”按SERP页面报告中位数
> tapply(theResults $ moz_upa,theResults $ rankBin,中位数)
第1页第2页
43 39
总之,来自两个Moz API变量的两个分布非常不同。但是两者都显示出SERP页面之间分数的差异,并且为您提供了切实的价值(中位数),可以与您合作并最终为客户提供关于您自己的SEO的建议。
当然,这只是一个小样本,不应该从字面上理解。但是,借助Google和Moz的免费资源,您现在可以看到如何开始开发自己的分析功能,以使假设基于而不是接受规范。 SEO排名因素一直在变化,拥有自己的分析工具来进行自己的测试和实验将帮助您提高信誉,甚至可能对迄今未知的事物提供独特的见解。
Google为您提供了健康的免费配额,可从中获取搜索结果。如果您需要的免费Moz数量超过每月2500行,则有 众多付费计划 您可以购买。 MySQL是一个 免费下载 并且R也是一个 免费包装 用于统计分析(以及更多)。
去探索!