
[ad_1]
在任何领域做出的最困难的决定之一是有意识地选择错过最后期限。 在过去的几个月中,由一些最聪明的工程师,数据科学家,项目经理,编辑和营销人员组成的团队 努力争取新的页面授权机构(PA)的发布日期 到2020年9月30日。新模型几乎在所有方面都不同于当前的功率放大器,但我们最近的质量控制措施显示了我们不能忽略的异常情况。
因此,我们做出了艰难的决定,推迟了Page Authority 2.0的发布。 因此,让我花点时间回顾一下我们如何到达这里,离开我们的地方以及我们打算如何进行的步骤。
睁大眼睛看老问题
从历史上看,Moz反复使用相同的方法来建立Page Authority模型(以及Domain Authority)。 该模型的优点是它的简单性,但是还有很多不足之处。
上一页页面授权模型针对SERP进行了训练,试图根据从链接资源管理器反向链接索引计算出的一组链接度量标准来预测一个URL是否会在另一个URL上排名。 这种类型的模型的关键问题是,它无法有意义地解决一组特定链接指标的最大强度。
例如,想象一下Internet上最强大的URL,这些URL的链接是:Google,Youtube,Facebook的主页,或跟随的社交网络按钮的共享URL。 没有任何SERP可以使这些URL相互抵触。 取而代之的是,这些功能非常强大的URL通常排名第一,其后的指标则大大降低。 试想一下,如果迈克尔·乔丹,科比·布莱恩特和勒布朗·詹姆斯各自对高中生都一对一地抓紧时间。 每个人每次都会赢。 但是,从迈克尔·乔丹,科比·布莱恩特或勒布朗·詹姆斯是否会在一对一的比赛中获胜,我们很难从这些结果中推断出来。
当负责重新访问域授权时,我们最终选择了一个拥有丰富经验的模型:原始的SERP培训方法(尽管有很多调整)。 借助Page Authority,我们决定通过预测哪个页面的自然访问量会更多,一起采用另一种培训方法。 该模型提出了一些有希望的品质,例如能够比较不在同一SERP上出现的URL,但是还提出了其他困难,例如页面具有较高的链接公平性,而只是处于不经常搜索的主题区域中。 我们解决了许多此类问题,例如增强培训集,以使用非链接指标来衡量竞争力。
衡量新的Page Authority的质量
结果是而且非常令人鼓舞。
首先,新模型显然预测了一页将比另一页拥有更多有价值的自然流量的可能性。 这是预料之中的,因为新模型是针对此特定目标的,而当前的“页面授权机构”仅试图预测一个页面是否会排在另一页面之上。
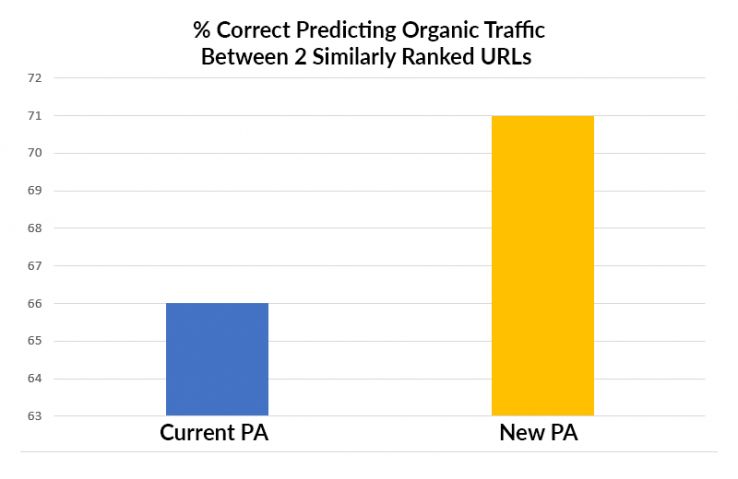
其次,我们发现,新模型预测的一页是否比以前的Page Authority更好。 这特别令人愉悦,因为它使我们许多担忧,因为新的培训模型使新模型在旧质量控制方面表现不佳。
新模型在预测SERP方面比当前的PA好多少? 在每个时间间隔(一直下降到位置4对5)上,新模型都与当前模型并列或表现不佳。 它永远不会丢失。
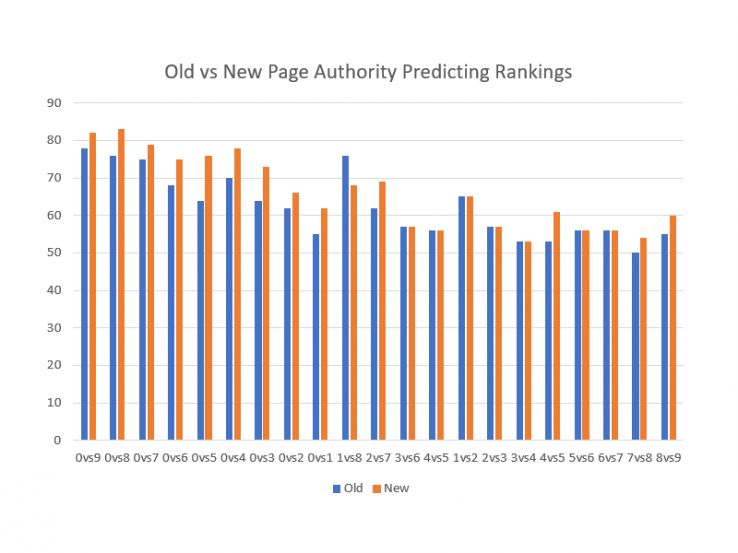
一切都很好。 然后,我们开始分析异常值。 我喜欢称其为“看起来愚蠢吗?” 测试。 机器学习会像人类一样犯错误,但是人类倾向于以非常特殊的方式犯错误。 当一个人犯了一个错误时,我们经常会确切地理解为什么会犯错。 ML并非如此,尤其是神经网络。 我们在新的模式下将碰巧具有零自然访问量的URL的URL授予了URL,并将其包含在训练集中以学习这些错误。 我们很快就看到90+的奇异PA下降到了更合理的60和70年代……又是一个胜利。
我们进行了最后一次测试。
品牌搜索的问题
网络上一些最受欢迎的关键字是导航性的。 人们在Google上搜索Facebook,Youtube,甚至Google本身。 这些关键字相对于其他关键字的搜索量是天文数字。 随后,少数几个强大的品牌可能会对将总搜索量作为其核心培训目标一部分的模型产生巨大影响。
最后一个测试包括将当前的页面授权机构与新的页面授权机构进行比较,以确定是否存在任何离奇的异常值(PA发生明显变化且没有明显原因)。 首先,让我们看一下链接根域的LOG与页面权限的简单比较。

不是太寒酸。 我们看到链接根域和页面权限之间通常呈正相关。 但是你能发现奇怪之处吗? 继续,花一点时间…
此图表中有两个异常现象:
- URL的主要分布与上方和下方的异常值之间存在一个奇怪的鸿沟。
- 单个分数的最大差异是PA99。PA99的数量很多,具有广泛的链接根域。
这是一个可视化视图,将有助于找出这些异常:

绿色和红色之间的灰色空间代表分布的大部分与离群值之间的奇数间隙。 异常值(红色)趋于聚集在一起,尤其是在主要分布上方。 当然,我们可以看到PA 99s顶部的分布不均。
请记住,这些问题不足以使新的Page Authority模型不如当前模型更准确。 但是,在进一步检查后,我们发现该模型确实产生的错误非常严重,足以对客户的决策产生不利影响。 最好有一个到处都有一点点偏离的模型(因为SEO所做的调整没有得到令人难以置信的微调),比拥有一个几乎在所有地方都正确但在少数情况下异常错误的模型要好。
幸运的是,我们对问题出在哪里很有信心。 似乎首页的PA膨胀得过高,可能的罪魁祸首是训练集。 在我们完成再培训之前,我们无法确定这是原因,但这是一个强有力的线索。
好消息和坏消息
就目前而言,我们处于良好状态,因为我们拥有多个胜过现有Page Authority的候选模型。 我们正处在漏洞压缩的阶段,而不是模型构建。 但是,除非我们有信心它将引导我们的顾客朝正确的方向发展,否则我们不会发布新的分数。 我们高度重视客户根据我们的指标做出的决策,而不仅仅是这些指标是否满足某些统计标准。
考虑到所有这些,我们决定推迟启动Page Authority 2.0。 这将为我们提供必要的时间来解决这些主要问题并制定出出色的指标。 令人沮丧吗? 是的,但也有必要。
与往常一样,我们感谢您的耐心配合,我们期待产生我们有史以来发布的最佳Page Authority指标。