
[ad_1]
不久前,我和我的高级网络排名同事想出了一个 HTML学习 基于从Google排名前20位的搜索结果中收集的大约800万个索引页,其中包含3000万个关键字。
我们写了关于 标记结果 以及排名前20的Google结果页如何实现它们,然后进一步进行操作并获得HTML 使用见解 在他们。
这与SEO有什么关系?
HTML的编写方式决定了用户看到的内容以及搜索引擎如何解释网页。有效,格式正确的HTML页面还可以减少搜索引擎可能对结构化数据,元数据,语言或编码的误解。
我们打算从一开始就做一次技术性SEO审核:HTML用法的细分以及结果与现代SEO技术和最佳实践的关系。
在本文中,我们将解决Google可以理解的元标记,JSON-LD结构化数据,语言检测,标题用法,社交链接和元分布,AMP等问题。
Google可以理解的元标记
当谈到主要的搜索引擎作为流量来源时,可悲的是只有谷歌和其余的人,最近Duckduckgo获得了关注,Bing几乎不存在。
因此,在本节中,我们将仅关注Google在 Search Console帮助中心。
.png") 饼图显示了Google可以理解的meta标签总数,以下部分对此进行了详细说明。
饼图显示了Google可以理解的meta标签总数,以下部分对此进行了详细说明。
元描述是〜150个字符的摘要,总结了页面的内容。当搜索的短语包含在描述中时,搜索引擎会在搜索结果中显示元描述。
|
选择器 |
计数 |
|---|---|
|
4,391,448 |
|
|
374,649 |
|
|
13,831 |
在极端情况下,我们发现了685,341个元内容少于30个字符的元和1,293,842个元内容文本超过160个字符的元。
</h3>
<p>从技术上讲,标题不是meta标记,而是与meta name =“ description”结合使用。</p>
<p>当涉及SEO时,这是两个最重要的HTML标签之一。根据W3C,这也是必须的,这意味着缺少标题标签的任何页面均无效。</p>
<p>研究表明,如果您<a href="https://moz.com/learn/seo/title-tag" data-wpel-link="external" target="_self" rel="nofollow external noopener noreferrer"> 标题保持在60个字符以内</a> 那么您可以期望您的标题可以在SERP中正确呈现。过去,有迹象表明Google的搜索结果标题长度有所延长,但这并不是永久性的变化。</p>
<p>考虑到以上所有内容,我们发现在全部6,263,396个标题中,有1,846,642个标题标签似乎太长(超过60个字符),而1,985,020个标题的长度却认为太短(少于30个字符)。</p>
<p><img decoding="async" alt="titles.png" src="https://wpjian.com/wp-content/uploads/2019/10/5d9ce8753cb0a0.97189359.png" width="624" height="280" data-image="t20qt2hyesi2" title="titles.png">饼状图显示了标题标签的长度分布,长度小于30个字符为31.7%,长度大于60个字符为约29.5%。</p>
<p>标题太短不应该成为问题-毕竟,这取决于网站业务,是主观的。意义可以用更少的词来表达,但这绝对是优化机会浪费的迹象。</p>
<table class="table-basic table-row-hover">
<thead>
<tr>
<th>
<p>选择器</p>
</th>
<th>
<p>计数</p>
</th>
</tr>
</thead>
<tr>
<td><title>*
6,263,396
失踪 标签</td>
<td>
<p>1,285,738</p>
<p>
</td>
</tr>
</table>
<p>另一个有趣的事情是,在Google的第1-2页上排名的网站中,有351,516个(约占750万个的5%)在其索引页上使用相同的标题和h1文本。</p>
<p>另外,您知道吗,使用HTML5,您只需要指定HTML5文档类型和标题即可拥有完全有效的页面?</p>
<p><!DOCTYPE html><br />
<title>红色
这些元标记可以控制搜索引擎抓取和编制索引的行为。 robots元标记适用于所有搜索引擎,而“ googlebot”元标记特定于Google。”
— Google可以理解的元标记
选择器
计数
1,577,202
139,458
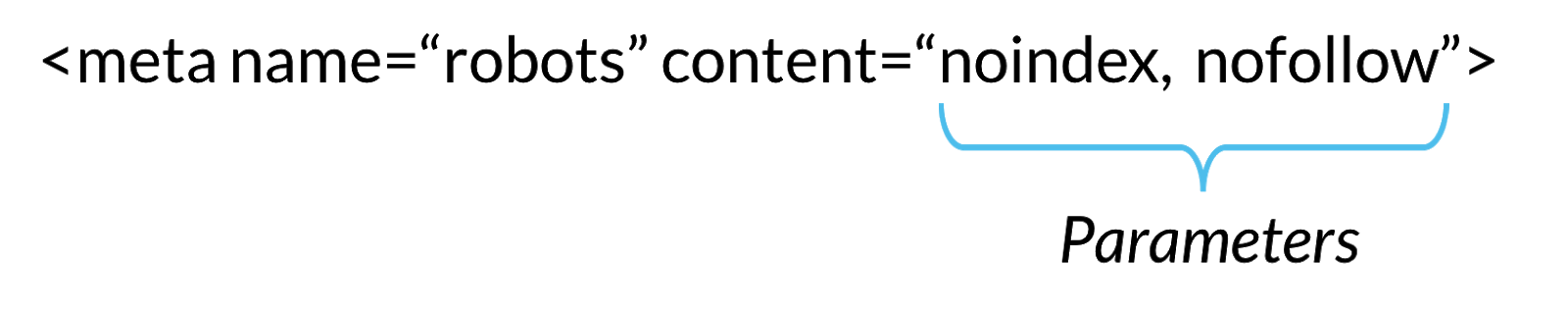 带有元漫游器的HTML代码段及其内容参数。
带有元漫游器的HTML代码段及其内容参数。
所以 机器人元指令 向搜索引擎提供有关如何对页面内容进行爬网和编制索引的说明。抛开Googlebot元计数这一低点,我们好奇地看到了最频繁的机器人参数,考虑到 误解是您必须添加一个机器人元 在您的HTML头部标记。这是前5名:
选择器
计数
632822
180,226
115,128
111,777
83,639
“当用户搜索您的网站时,Google搜索结果有时会显示特定于您网站的搜索框,以及指向您网站的其他直接链接。此元标记告诉Google不要显示附加链接搜索框。”
— Google可以理解的元标记
选择器
计数
1,263
毫不奇怪,当网站出现在搜索结果中时,很少有网站选择明确告诉Google不要显示附加链接搜索框。
“此meta标签告诉Google您不希望我们为该页面提供翻译。”- Google可以理解的元标记
在某些情况下,可能不希望将您的内容提供给更多的用户。就像上面的Google支持答案中所说的那样,此meta标签告诉Google您不希望他们提供此页面的翻译。
选择器
计数
7,569
“您可以在网站的顶级页面上使用此标记来验证Search Console的所有权。”
— Google可以理解的元标记
选择器
计数
1,327,616
当我们讨论这个主题时,您是否知道如果您是Google Analytics(分析)媒体资源的经过验证的所有者,那么Google现在将 自动验证 Search Console中的那个网站?
“这定义了页面的内容类型和字符集。”
— Google可以理解的元标记
这基本上是好的元标记之一。它定义页面的内容类型和字符集。考虑到下表,我们注意到我们分析的索引页中只有大约一半定义了元字符集。
选择器
计数
3,909,788
“此元标记在一定时间后会将用户发送到新的URL,有时被用作一种简单的重定向形式。”
— Google可以理解的元标记
最好使用301重定向而不是元刷新来重定向您的网站,尤其是当我们假设 30倍重定向不会丢失PageRank 和W3C 建议不要使用此标签。 Google也不是粉丝,建议您使用服务器端301重定向。
选择器
计数
7,167
从我们解析的总共750万个索引页中,我们发现了7167个使用上述重定向方法的页。作者并不总是拥有对服务器端技术的控制权,显然他们使用此技术来启用客户端重定向。
也, 使用工人 是解决与传统技术堆栈和平台局限性时遇到的问题的一种尖端替代方案。
“此标签告诉浏览器如何在移动设备上呈现页面。此标签的存在向Google表示该页面适合移动设备。”
— Google可以理解的元标记
选择器
计数
4,992,791
从2019年7月1日开始,所有网站开始使用Google的索引 移动优先索引。 Lighthouse检查文件头中是否有meta name =“ viewport”标记,因此无论您使用的是哪种框架或CMS,此meta都应位于每个网页上。
考虑到上述情况,我们可以预期在分析的750万个索引页面中,有超过4,992,791个网站的网站在其头部使用了有效的meta name =“ viewport”。
设计适合移动设备的网站可确保您的网页在所有设备上都能正常运行,因此请确保您的页面 网页适合移动设备 这里。
“将页面标记为包含成人内容,以表明该页面已被安全搜索结果过滤。”
— Google可以理解的元标记
选择器
计数
133,387
此标签用于表示内容的成熟度等级。直到最近,它才被添加到Google可以理解的meta标签中。看看Kate Morris的这篇文章, 如何标记成人内容。
JSON-LD结构化数据
结构化数据 是用于提供有关页面信息和对页面内容进行分类的标准化格式。结构化数据的格式可以是Microdata,RDFa和JSON-LD,所有这些都可以帮助Google了解您网站的内容并触发页面的特殊搜索结果功能。
与真棒交谈时 丹舒尔,他提出了一个好主意,可以在搜索结果和“知识图”中查找结构化数据,例如组织的徽标。
在本部分中,我们将仅使用JSON-LD(用于链接数据的JavaScript对象表示法)来收集结构化数据信息。这就是Google的建议 无论如何提供有关网页含义的线索。
一些有用的信息:
- 在Google I / O 2019上宣布 结构化数据 测试工具将由 丰富的结果 测试工具。
- 现在,Googlebot使用 最新铬 而不是旧的Chrome 42,这意味着您还可以通过结构化数据支持来减轻过去可能遇到的SEO问题。
-
杰森·巴纳德(Jason Barnard) 在SMX London 2019上进行了有趣的演讲 Google搜索排名如何工作 根据他的理论,我们可以依靠七个排名因素。结构化数据绝对是其中之一。
-
内置可见的Microdata,JSON-LD和Schema.org指南包含了有关在网站上使用结构化数据所需了解的所有信息。
- 这真棒 JSON-LD入门指南 通过 亚历克西斯·桑德斯(Alexis Sanders)。
- 最后但并非最不重要的一点是,有很多文章,演示文稿和帖子可供正式使用 JSON用于链接数据 网站。
高级网络排名的HTML研究仅依赖于分析索引页面。有趣的是,即使准则中未对此进行说明,但Google似乎并不关心索引页上的结构化数据,如 堆栈溢出答案 由Gary Illyes于几年前撰写。但是,在JSON-LD结构上 Google可以理解的数据类型,我们发现了总共2,727,045个功能:
 饼图显示了Google可以理解的结构化数据类型,其中“附加链接”搜索框为49.7%(最高值)。
饼图显示了Google可以理解的结构化数据类型,其中“附加链接”搜索框为49.7%(最高值)。
结构化数据功能
计数
文章
35,961
面包屑
30,306
书
143
轮播
13,884
公司联系方式
41,588
课程
676
评论家评论
2,740
数据集
28
雇主总评分
7
事件
18,385
事实检查
7
常见问题页面
16
如何
8
招聘启事
355
现场直播
232
当地的商业
200,974
商标
442,324
媒体
1,274
占用
0
产品
16,090
问答页面
20
食谱
434
评论片段
72,732
网站连结搜寻框
1,354,754
社会概况
478,099
软件应用
780
可以说
516
订阅和付费内容
363
视频
14,349
rel =规范
rel = canonical元素(通常称为“规范链接”)是一种HTML元素,可帮助网站管理员防止重复的内容问题。它通过指定“规范URL”(网页的“首选”版本)来实现。
选择器
计数
3,183,575
meta name =“ keywords”
这不是新的 已经过时了 Google不再使用它。看起来好像 是大多数搜索引擎的垃圾邮件信号。
“尽管主要搜索引擎不使用元关键字进行排名,但它们对于诸如Solr之类的现场搜索引擎非常有用。”
— JP谢尔曼 关于为什么这个过时的meta在当今仍然有用的原因。
选择器
计数
2,577,850
256,220
14,127
标题
在750万页中,h1(59.6%)和h2(58.9%)是使用最多的28个元素之一。尽管如此,在收集所有标题后,我们发现h3是出现次数最多的标题-在找到的总标题70,428,376中,有29,565,562个h3。
随机事实:
- h1-h6元素代表节标题的六个级别。这里有 标题用法的完整统计信息,但我们也找到了23116个h7和7276个h8。这很有趣,因为很多 人们甚至不使用h6s 常常。
- 共有3,046,879个页面缺少h1标签,在其余4,502,255页中,h1的使用频率为2.6,共有11,675,565个h1元素。
- 如上所示,虽然有6,263,396个页面的有效标题,但只有4,502,255个页面的内容正文中使用h1。
缺少alt标签
分析这组数据后,这个永恒的SEO和可访问性问题似乎仍然很常见。在总共669,591,743张图像中,几乎90%缺少alt属性或将其与空白值一起使用。
.png") 饼状图显示了img标签的alt属性分布,其中缺失的alt占主导地位-在我们发现的约6.7亿张图像中,占81.7%。
饼状图显示了img标签的alt属性分布,其中缺失的alt占主导地位-在我们发现的约6.7亿张图像中,占81.7%。
选择器
计数
img
669,591,743
img alt =“ *”
79,953,034
img alt =“”
42,815,769
img w / missing alt
546,822,940
语言检测
根据 眼镜,用户代理可以使用通过lang属性指定的语言信息以多种方式控制渲染。
我们在此处感兴趣的部分是有关“辅助搜索引擎”的。
“ HTML lang属性用于识别网络上文本内容的语言。这些信息有助于搜索引擎返回特定于语言的结果,屏幕阅读器也可以使用这些信息来切换语言配置文件,以提供正确的口音和发音。”
— 莱妮·沃森
不久前,约翰·穆勒(John Mueller)说 Google忽略HTML lang属性 并建议使用 链接hreflang 代替。 Google Search Console文档指出,Google使用hreflang标记将用户的语言偏好与页面的正确变体进行匹配。
 条形图显示750万个索引页中有65%使用html元素上的lang属性,同时21.6%至少使用链接hreflang。
条形图显示750万个索引页中有65%使用html元素上的lang属性,同时21.6%至少使用链接hreflang。
在我们可以查看的750万个索引页中,有4,903,665个使用html元素上的lang属性。大约是65%!
关于hreflang属性,这表明存在一个多语言网站,我们发现大约1,631,602个页面-意味着大约21.6%的索引页面至少使用一个链接rel =“ alternate” href =“ *” hreflang =“ *”元素。
Google跟踪代码管理器
从一开始,Google Analytics(分析)的主要任务就是生成有关您的网站的报告和统计信息。但是,如果要将某些页面分组在一起以查看人们如何浏览该渠道,则需要一个唯一的Google Analytics(分析)标签。这就是事情变得复杂的地方。
Google Tag Manager使您可以更轻松地进行以下操作:
- 通过让您定义标签应触发的时间和用户操作的自定义规则,来管理这些混乱的标签
- 随时更改标签,而无需实际更改网站的源代码,由于发布周期缓慢,有时可能会令人头疼
- 再次与GTM一起使用其他分析/营销工具,而无需触及网站的源代码
我们搜索了* googletagmanager.com / gtm.js参考资料,发现大约有345,979个页面正在使用Google跟踪代码管理器。
rel =“ nofollow”
“ Nofollow”为网站管理员提供了一种告诉搜索引擎“不遵循此页面上的链接”或“不遵循此特定链接”的方法。
Google不遵循这些链接,并且同样不转让权益。考虑到这一点,我们对rel =“ nofollow”数字感到好奇。我们在750万个索引页面中找到了总共12,828,286个rel =“ nofollow”链接,计算得出的平均每页为1.69 rel =“ nofollow”。
上个月, Google宣布了两个新的链接属性值 应该用来标记链接的nofollow属性:rel =“ sponsored”和rel =“ ugc”。我建议您阅读Cyrus Shepard在 Google的nofollow,赞助商和ugc链接如何影响SEO,了解Google为何更改nofollow,nofollow链接对排名的影响等。
 赛勒斯·谢泼德(Cyrus Shepard)的文章显示了一张表格,该表格显示了Google的nofollow,Sponsored和UGC链接属性如何影响SEO。
赛勒斯·谢泼德(Cyrus Shepard)的文章显示了一张表格,该表格显示了Google的nofollow,Sponsored和UGC链接属性如何影响SEO。
我们进一步研究了这些新的链接属性值,找到了278 rel =“ sponsored”和123 rel =“ ugc”。为了确保我们拥有与这些查询相关的数据,我们专门在Google宣布此事后两周更新了索引页数据集。然后,使用Moz授权指标,我们筛选出使用至少rel =“ sponsored”或rel =“ ugc”对之一的顶级URL:
- https://www.seroundtable.com/
- https://letsencrypt.org/
- https://www.newsbomb.gr/
- https://thehackernews.com/
- https://www.ccn.com/
- https://www.chip.pl/
- https://www.gamereactor.se/
- https://www.tribes.co.uk/
安培
加速的移动页面(AMP) 是Google的一项举措,旨在加快移动网络的发展。许多发布者正在使其内容与AMP格式并行可用。
为了让Google和其他平台了解这一点,您需要将AMP和非AMP页面链接在一起。
在我们浏览的数百万个页面中,我们发现只有24,807个非AMP页面使用rel = amphtml引用其AMP版本。
社会的
我们想知道当今网站的可共享性或社交性,因此 乔什·布奇亚(Josh Buchea) 做了一个很棒的清单 一切可能进入脑海 您的网页中,我们从那里提取了社交部分,并获得了以下数字:
Facebook开放图
 条形图显示了Facebook Open Graph元标记的分布,在下表中进行了详细说明。
条形图显示了Facebook Open Graph元标记的分布,在下表中进行了详细说明。
选择器
计数
元属性=“ fb:app_id” content =“ *”
277,406
元属性=“ og:url”内容=“ *”
2,909,878
元属性=“ og:type” content =“ *”
2,660,215
元属性=“ og:title” content =“ *”
3,050,462
元属性=“ og:image” content =“ *”
2,603,057
元属性=“ og:image:alt” content =“ *”
54,513
元属性=“ og:description” content =“ *”
1,384,658
元属性=“ og:site_name” content =“ *”
2,618,713
元属性=“ og:locale” content =“ *”
1,384,658
元属性=“ article:author” content =“ *”
14,289
Twitter卡
.png") 条形图显示了Twitter Card meta标签的分布,在下表中有详细说明。
条形图显示了Twitter Card meta标签的分布,在下表中有详细说明。
选择器
计数
元名称=“ twitter:card” content =“ *”
1,535,733
元名称=“ twitter:site” content =“ *”
512,907
元名称=“ twitter:creator” content =“ *”
283,533
元名称=“ twitter:url” content =“ *”
265,478
元名称=“ twitter:title” content =“ *”
716,577
元名称=“ twitter:description” content =“ *”
1,145,413
元名称=“ twitter:image” content =“ *”
716,577
元名称=“ twitter:image:alt” content =“ *”
30,339
说到链接,我们抓住了所有指向最受欢迎的社交网络的链接。
.png") 下表显示了外部社交链接分布的饼图。
下表显示了外部社交链接分布的饼图。
选择器
计数
6,180,313
5,214,768
1,148,828
1,019,970
显然,仍有许多网站仍链接到其Google+个人资料,这可能是出于疏忽考虑 Google+关闭。
rel =上一个/下一个
Google表示,使用rel = prev / next不再是索引信号,正如今年早些时候宣布的那样:
“在评估索引信号时,我们决定停用rel = prev / next。研究表明,用户喜欢单页内容,在可能的情况下尽量做到这一点,但对于Google搜索来说,多部分内容也可以。
— 由Google网站管理员发布
但是,如果对您来说很重要,Bing表示它将它们用作提示以发现页面和了解网站结构。
“我们将这些标记(如大多数标记)用作页面发现和网站结构理解的提示。此时,我们不会基于这些页面将页面合并在一起,也不会在排名模型中使用prev / next。”
— 弗雷德里克·杜布(FrédéricDubut) 从必应
不过,这是我们在查看数百万个索引页面时发现的使用情况统计信息:
选择器
计数
<link rel =“ prev” href =“ *”
20,160
<link rel =“ next” href =“ *”
242,387
差不多了!
通过使用约800万个索引页面中的数据了解平均网页的外观,可以使我们更清楚地了解趋势,并帮助我们可视化涉及SEO现代和新兴技术的HTML的常见用法。但这可能是一个永无止境的传奇-尽管有很多数字和统计数据需要探索,但仍有许多问题需要回答:
- 我们知道现在如何在野外使用结构化数据。它将如何发展,将足够考虑多少结构化数据?
- 我们是否应该期望AMP使用量将来会增加?
- rel =“ sponsored”和rel =“ ugc”将如何改变我们每天编写HTML的方式?在编码外部链接时,除了target =“ _ blank”和rel =“ noopener”组合之外,我们现在必须考虑rel =“ sponsored”和rel =“ ugc”组合也是如此。
- 我们是否会学会始终为具有装饰目的的图像添加alt属性值?
- 我们必须将多少其他元标记或属性添加到网页中,才能取悦搜索引擎?我们真的需要新宣布的 数据片段 HTML属性?下一步是什么, 数据允许摘要?
我们还希望解决其他问题,例如与排名密切相关的“第一字节时间''(TTFB)值;我强烈推荐 HTTP档案 为了那个原因。他们定期抓取Web上的热门站点,并记录有关几乎所有内容的详细信息。根据最新信息,他们已经分析了 4,565,694个独特网站,具有完整的Lighthouse评分,并为整个数据集存储了jQuery或WordPress等特定技术。巨大的道具 里克·维斯科米 他喜欢称呼自己为“管家”,表现出色。
进行这项大规模研究很有趣。我们学到了很多东西,希望您发现上面的数字和我们一样有趣。如果您特别想查看标签或属性,请在下面的评论中让我知道。
再次检查 完整的HTML学习结果 让我知道你的想法!
6,263,396
这些元标记可以控制搜索引擎抓取和编制索引的行为。 robots元标记适用于所有搜索引擎,而“ googlebot”元标记特定于Google。”
— Google可以理解的元标记
|
选择器 |
计数 |
|---|---|
|
1,577,202 |
|
|
139,458 |
带有元漫游器的HTML代码段及其内容参数。
所以 机器人元指令 向搜索引擎提供有关如何对页面内容进行爬网和编制索引的说明。抛开Googlebot元计数这一低点,我们好奇地看到了最频繁的机器人参数,考虑到 误解是您必须添加一个机器人元 在您的HTML头部标记。这是前5名:
|
选择器 |
计数 |
|---|---|
|
632822 |
|
|
180,226 |
|
|
115,128 |
|
|
111,777 |
|
|
83,639 |
“当用户搜索您的网站时,Google搜索结果有时会显示特定于您网站的搜索框,以及指向您网站的其他直接链接。此元标记告诉Google不要显示附加链接搜索框。”
— Google可以理解的元标记
|
选择器 |
计数 |
|---|---|
|
1,263
|
毫不奇怪,当网站出现在搜索结果中时,很少有网站选择明确告诉Google不要显示附加链接搜索框。
“此meta标签告诉Google您不希望我们为该页面提供翻译。”- Google可以理解的元标记
在某些情况下,可能不希望将您的内容提供给更多的用户。就像上面的Google支持答案中所说的那样,此meta标签告诉Google您不希望他们提供此页面的翻译。
|
选择器 |
计数 |
|---|---|
|
7,569 |
“您可以在网站的顶级页面上使用此标记来验证Search Console的所有权。”
— Google可以理解的元标记
|
选择器 |
计数 |
|---|---|
|
1,327,616 |
当我们讨论这个主题时,您是否知道如果您是Google Analytics(分析)媒体资源的经过验证的所有者,那么Google现在将 自动验证 Search Console中的那个网站?
“这定义了页面的内容类型和字符集。”
— Google可以理解的元标记
这基本上是好的元标记之一。它定义页面的内容类型和字符集。考虑到下表,我们注意到我们分析的索引页中只有大约一半定义了元字符集。
|
选择器 |
计数 |
|---|---|
|
3,909,788 |
“此元标记在一定时间后会将用户发送到新的URL,有时被用作一种简单的重定向形式。”
— Google可以理解的元标记
最好使用301重定向而不是元刷新来重定向您的网站,尤其是当我们假设 30倍重定向不会丢失PageRank 和W3C 建议不要使用此标签。 Google也不是粉丝,建议您使用服务器端301重定向。
|
选择器 |
计数 |
|---|---|
|
7,167 |
从我们解析的总共750万个索引页中,我们发现了7167个使用上述重定向方法的页。作者并不总是拥有对服务器端技术的控制权,显然他们使用此技术来启用客户端重定向。
也, 使用工人 是解决与传统技术堆栈和平台局限性时遇到的问题的一种尖端替代方案。
“此标签告诉浏览器如何在移动设备上呈现页面。此标签的存在向Google表示该页面适合移动设备。”
— Google可以理解的元标记
|
选择器 |
计数 |
|---|---|
|
4,992,791 |
从2019年7月1日开始,所有网站开始使用Google的索引 移动优先索引。 Lighthouse检查文件头中是否有meta name =“ viewport”标记,因此无论您使用的是哪种框架或CMS,此meta都应位于每个网页上。
考虑到上述情况,我们可以预期在分析的750万个索引页面中,有超过4,992,791个网站的网站在其头部使用了有效的meta name =“ viewport”。
设计适合移动设备的网站可确保您的网页在所有设备上都能正常运行,因此请确保您的页面 网页适合移动设备 这里。
“将页面标记为包含成人内容,以表明该页面已被安全搜索结果过滤。”
— Google可以理解的元标记
|
选择器 |
计数 |
|---|---|
|
133,387 |
|
此标签用于表示内容的成熟度等级。直到最近,它才被添加到Google可以理解的meta标签中。看看Kate Morris的这篇文章, 如何标记成人内容。
JSON-LD结构化数据
结构化数据 是用于提供有关页面信息和对页面内容进行分类的标准化格式。结构化数据的格式可以是Microdata,RDFa和JSON-LD,所有这些都可以帮助Google了解您网站的内容并触发页面的特殊搜索结果功能。
与真棒交谈时 丹舒尔,他提出了一个好主意,可以在搜索结果和“知识图”中查找结构化数据,例如组织的徽标。
在本部分中,我们将仅使用JSON-LD(用于链接数据的JavaScript对象表示法)来收集结构化数据信息。这就是Google的建议 无论如何提供有关网页含义的线索。
一些有用的信息:
- 在Google I / O 2019上宣布 结构化数据 测试工具将由 丰富的结果 测试工具。
- 现在,Googlebot使用 最新铬 而不是旧的Chrome 42,这意味着您还可以通过结构化数据支持来减轻过去可能遇到的SEO问题。
- 杰森·巴纳德(Jason Barnard) 在SMX London 2019上进行了有趣的演讲 Google搜索排名如何工作 根据他的理论,我们可以依靠七个排名因素。结构化数据绝对是其中之一。
- 内置可见的Microdata,JSON-LD和Schema.org指南包含了有关在网站上使用结构化数据所需了解的所有信息。
- 这真棒 JSON-LD入门指南 通过 亚历克西斯·桑德斯(Alexis Sanders)。
- 最后但并非最不重要的一点是,有很多文章,演示文稿和帖子可供正式使用 JSON用于链接数据 网站。
高级网络排名的HTML研究仅依赖于分析索引页面。有趣的是,即使准则中未对此进行说明,但Google似乎并不关心索引页上的结构化数据,如 堆栈溢出答案 由Gary Illyes于几年前撰写。但是,在JSON-LD结构上 Google可以理解的数据类型,我们发现了总共2,727,045个功能:
饼图显示了Google可以理解的结构化数据类型,其中“附加链接”搜索框为49.7%(最高值)。
|
结构化数据功能 |
计数 |
|---|---|
|
文章 |
35,961 |
|
面包屑 |
30,306 |
|
书 |
143 |
|
轮播 |
13,884 |
|
公司联系方式 |
41,588 |
|
课程 |
676 |
|
评论家评论 |
2,740 |
|
数据集 |
28 |
|
雇主总评分 |
7 |
|
事件 |
18,385 |
|
事实检查 |
7 |
|
常见问题页面 |
16 |
|
如何 |
8 |
|
招聘启事 |
355 |
|
现场直播 |
232 |
|
当地的商业 |
200,974 |
|
商标 |
442,324 |
|
媒体 |
1,274 |
|
占用 |
0 |
|
产品 |
16,090 |
|
问答页面 |
20 |
|
食谱 |
434 |
|
评论片段 |
72,732 |
|
网站连结搜寻框 |
1,354,754 |
|
社会概况 |
478,099 |
|
软件应用 |
780 |
|
可以说 |
516 |
|
订阅和付费内容 |
363 |
|
视频 |
14,349 |
rel =规范
rel = canonical元素(通常称为“规范链接”)是一种HTML元素,可帮助网站管理员防止重复的内容问题。它通过指定“规范URL”(网页的“首选”版本)来实现。
|
选择器 |
计数 |
|---|---|
|
3,183,575 |
meta name =“ keywords”
这不是新的 已经过时了 Google不再使用它。看起来好像 是大多数搜索引擎的垃圾邮件信号。
“尽管主要搜索引擎不使用元关键字进行排名,但它们对于诸如Solr之类的现场搜索引擎非常有用。”
— JP谢尔曼 关于为什么这个过时的meta在当今仍然有用的原因。
|
选择器 |
计数 |
|---|---|
|
2,577,850 |
|
|
256,220 |
|
|
14,127 |
标题
在750万页中,h1(59.6%)和h2(58.9%)是使用最多的28个元素之一。尽管如此,在收集所有标题后,我们发现h3是出现次数最多的标题-在找到的总标题70,428,376中,有29,565,562个h3。
随机事实:
- h1-h6元素代表节标题的六个级别。这里有 标题用法的完整统计信息,但我们也找到了23116个h7和7276个h8。这很有趣,因为很多 人们甚至不使用h6s 常常。
- 共有3,046,879个页面缺少h1标签,在其余4,502,255页中,h1的使用频率为2.6,共有11,675,565个h1元素。
- 如上所示,虽然有6,263,396个页面的有效标题,但只有4,502,255个页面的内容正文中使用h1。
缺少alt标签
分析这组数据后,这个永恒的SEO和可访问性问题似乎仍然很常见。在总共669,591,743张图像中,几乎90%缺少alt属性或将其与空白值一起使用。
饼状图显示了img标签的alt属性分布,其中缺失的alt占主导地位-在我们发现的约6.7亿张图像中,占81.7%。
|
选择器 |
计数 |
|---|---|
|
img |
669,591,743 |
|
img alt =“ *” |
79,953,034 |
|
img alt =“” |
42,815,769 |
|
img w / missing alt |
546,822,940 |
语言检测
根据 眼镜,用户代理可以使用通过lang属性指定的语言信息以多种方式控制渲染。
我们在此处感兴趣的部分是有关“辅助搜索引擎”的。
“ HTML lang属性用于识别网络上文本内容的语言。这些信息有助于搜索引擎返回特定于语言的结果,屏幕阅读器也可以使用这些信息来切换语言配置文件,以提供正确的口音和发音。”
— 莱妮·沃森
不久前,约翰·穆勒(John Mueller)说 Google忽略HTML lang属性 并建议使用 链接hreflang 代替。 Google Search Console文档指出,Google使用hreflang标记将用户的语言偏好与页面的正确变体进行匹配。
条形图显示750万个索引页中有65%使用html元素上的lang属性,同时21.6%至少使用链接hreflang。
在我们可以查看的750万个索引页中,有4,903,665个使用html元素上的lang属性。大约是65%!
关于hreflang属性,这表明存在一个多语言网站,我们发现大约1,631,602个页面-意味着大约21.6%的索引页面至少使用一个链接rel =“ alternate” href =“ *” hreflang =“ *”元素。
Google跟踪代码管理器
从一开始,Google Analytics(分析)的主要任务就是生成有关您的网站的报告和统计信息。但是,如果要将某些页面分组在一起以查看人们如何浏览该渠道,则需要一个唯一的Google Analytics(分析)标签。这就是事情变得复杂的地方。
Google Tag Manager使您可以更轻松地进行以下操作:
- 通过让您定义标签应触发的时间和用户操作的自定义规则,来管理这些混乱的标签
- 随时更改标签,而无需实际更改网站的源代码,由于发布周期缓慢,有时可能会令人头疼
- 再次与GTM一起使用其他分析/营销工具,而无需触及网站的源代码
我们搜索了* googletagmanager.com / gtm.js参考资料,发现大约有345,979个页面正在使用Google跟踪代码管理器。
rel =“ nofollow”
“ Nofollow”为网站管理员提供了一种告诉搜索引擎“不遵循此页面上的链接”或“不遵循此特定链接”的方法。
Google不遵循这些链接,并且同样不转让权益。考虑到这一点,我们对rel =“ nofollow”数字感到好奇。我们在750万个索引页面中找到了总共12,828,286个rel =“ nofollow”链接,计算得出的平均每页为1.69 rel =“ nofollow”。
上个月, Google宣布了两个新的链接属性值 应该用来标记链接的nofollow属性:rel =“ sponsored”和rel =“ ugc”。我建议您阅读Cyrus Shepard在 Google的nofollow,赞助商和ugc链接如何影响SEO,了解Google为何更改nofollow,nofollow链接对排名的影响等。
赛勒斯·谢泼德(Cyrus Shepard)的文章显示了一张表格,该表格显示了Google的nofollow,Sponsored和UGC链接属性如何影响SEO。
我们进一步研究了这些新的链接属性值,找到了278 rel =“ sponsored”和123 rel =“ ugc”。为了确保我们拥有与这些查询相关的数据,我们专门在Google宣布此事后两周更新了索引页数据集。然后,使用Moz授权指标,我们筛选出使用至少rel =“ sponsored”或rel =“ ugc”对之一的顶级URL:
- https://www.seroundtable.com/
- https://letsencrypt.org/
- https://www.newsbomb.gr/
- https://thehackernews.com/
- https://www.ccn.com/
- https://www.chip.pl/
- https://www.gamereactor.se/
- https://www.tribes.co.uk/
安培
加速的移动页面(AMP) 是Google的一项举措,旨在加快移动网络的发展。许多发布者正在使其内容与AMP格式并行可用。
为了让Google和其他平台了解这一点,您需要将AMP和非AMP页面链接在一起。
在我们浏览的数百万个页面中,我们发现只有24,807个非AMP页面使用rel = amphtml引用其AMP版本。
社会的
我们想知道当今网站的可共享性或社交性,因此 乔什·布奇亚(Josh Buchea) 做了一个很棒的清单 一切可能进入脑海 您的网页中,我们从那里提取了社交部分,并获得了以下数字:
Facebook开放图
条形图显示了Facebook Open Graph元标记的分布,在下表中进行了详细说明。
|
选择器 |
计数 |
|---|---|
| 元属性=“ fb:app_id” content =“ *” |
277,406 |
| 元属性=“ og:url”内容=“ *” |
2,909,878 |
| 元属性=“ og:type” content =“ *” |
2,660,215 |
| 元属性=“ og:title” content =“ *” |
3,050,462 |
| 元属性=“ og:image” content =“ *” |
2,603,057 |
| 元属性=“ og:image:alt” content =“ *” |
54,513 |
| 元属性=“ og:description” content =“ *” |
1,384,658 |
| 元属性=“ og:site_name” content =“ *” |
2,618,713 |
| 元属性=“ og:locale” content =“ *” |
1,384,658 |
| 元属性=“ article:author” content =“ *” |
14,289 |
Twitter卡
条形图显示了Twitter Card meta标签的分布,在下表中有详细说明。
|
选择器 |
计数 |
|---|---|
| 元名称=“ twitter:card” content =“ *” |
1,535,733 |
| 元名称=“ twitter:site” content =“ *” |
512,907 |
| 元名称=“ twitter:creator” content =“ *” |
283,533 |
| 元名称=“ twitter:url” content =“ *” |
265,478 |
| 元名称=“ twitter:title” content =“ *” |
716,577 |
| 元名称=“ twitter:description” content =“ *” |
1,145,413 |
| 元名称=“ twitter:image” content =“ *” |
716,577 |
| 元名称=“ twitter:image:alt” content =“ *” |
30,339 |
说到链接,我们抓住了所有指向最受欢迎的社交网络的链接。
下表显示了外部社交链接分布的饼图。
|
选择器 |
计数 |
|---|---|
|
6,180,313 |
|
|
5,214,768 |
|
|
1,148,828 |
|
|
1,019,970 |
显然,仍有许多网站仍链接到其Google+个人资料,这可能是出于疏忽考虑 Google+关闭。
rel =上一个/下一个
Google表示,使用rel = prev / next不再是索引信号,正如今年早些时候宣布的那样:
“在评估索引信号时,我们决定停用rel = prev / next。研究表明,用户喜欢单页内容,在可能的情况下尽量做到这一点,但对于Google搜索来说,多部分内容也可以。
— 由Google网站管理员发布
但是,如果对您来说很重要,Bing表示它将它们用作提示以发现页面和了解网站结构。
“我们将这些标记(如大多数标记)用作页面发现和网站结构理解的提示。此时,我们不会基于这些页面将页面合并在一起,也不会在排名模型中使用prev / next。”
— 弗雷德里克·杜布(FrédéricDubut) 从必应
不过,这是我们在查看数百万个索引页面时发现的使用情况统计信息:
|
选择器 |
计数 |
|---|---|
| <link rel =“ prev” href =“ *” |
20,160 |
| <link rel =“ next” href =“ *” |
242,387 |
差不多了!
通过使用约800万个索引页面中的数据了解平均网页的外观,可以使我们更清楚地了解趋势,并帮助我们可视化涉及SEO现代和新兴技术的HTML的常见用法。但这可能是一个永无止境的传奇-尽管有很多数字和统计数据需要探索,但仍有许多问题需要回答:
- 我们知道现在如何在野外使用结构化数据。它将如何发展,将足够考虑多少结构化数据?
- 我们是否应该期望AMP使用量将来会增加?
- rel =“ sponsored”和rel =“ ugc”将如何改变我们每天编写HTML的方式?在编码外部链接时,除了target =“ _ blank”和rel =“ noopener”组合之外,我们现在必须考虑rel =“ sponsored”和rel =“ ugc”组合也是如此。
- 我们是否会学会始终为具有装饰目的的图像添加alt属性值?
- 我们必须将多少其他元标记或属性添加到网页中,才能取悦搜索引擎?我们真的需要新宣布的 数据片段 HTML属性?下一步是什么, 数据允许摘要?
我们还希望解决其他问题,例如与排名密切相关的“第一字节时间''(TTFB)值;我强烈推荐 HTTP档案 为了那个原因。他们定期抓取Web上的热门站点,并记录有关几乎所有内容的详细信息。根据最新信息,他们已经分析了 4,565,694个独特网站,具有完整的Lighthouse评分,并为整个数据集存储了jQuery或WordPress等特定技术。巨大的道具 里克·维斯科米 他喜欢称呼自己为“管家”,表现出色。
进行这项大规模研究很有趣。我们学到了很多东西,希望您发现上面的数字和我们一样有趣。如果您特别想查看标签或属性,请在下面的评论中让我知道。
再次检查 完整的HTML学习结果 让我知道你的想法!