
[ad_1]
在我看来,这并不是以前所说的,但是Google为它的Knowledge Graph提供了一种算法。
我已经跟踪知识图谱API五年了。 resultScores一直以相当稳定的方式略有上升。
但是Google在2019年夏天更新了该算法。
真的,真的很重要。

此重大更新如何影响搜索生态系统尚待确定。
但这对于Google以及我们作为数字营销者来说都可能成为一个转折点。
在本文中,我将解释我要跟踪的内容,如何跟踪它,对上面的数据进行一些观察并提出一些理论。
请记住,这是新事物,我只是在评论自己的观点。我的目的是开始对话。 ?
Ping知识图API
五年来,我一直在收集Knowledge Graph API返回的信息。
自2019年初以来,我已经收集了有关Google的Knowledge Graph API返回的所有信息,这些信息涉及7,504个品牌和4,069个左右的名人。
没有什么比收集API返回的内容更复杂的了。以下所有数字均包括我跟踪的所有品牌和人员。
该API返回与与之配对的字符串相关联的实体列表。在这种情况下,品牌名称。
通常它什么也不返回。有时只是一个实体。有时会有十几个或更多实体。
当它返回多个实体时,它们由一个分数-resultScore-排序,我称之为“相关性”。
它返回的实体列表中的第一个结果是Google认为最相关的结果。
在什么意义上最相关?
我的阅读结果是,resultScore /相关性分数衡量两件事:
- Google对这是我们在查询中所指的实体的信心(即,它是否已将字符串匹配该实体)。
- 在含糊不清的情况下,根据Google的意图,哪个实体是最有可能的候选者。
- 如果不是直接与查询相对应的实体,则实体之间的关系有多紧密。
这是荷马·辛普森的结果
主要实体(最有可能)

次要(可能性较小)实体
这是完全相同查询的子结果/替代实体-相关性得分要低得多。
Google已经看到,字符串确实是指该实体,但是我们指的是该实体的概率大大低于虚构的字符。
实际上,在知识图谱中有五首歌叫做荷马·辛普森(Homer Simpson)–出于有趣的信息目的(并将Google含糊不清的令人难以置信的问题推回家),这些艺术家是:
- DJ炸弹杰克
- 斯科特和托德
- BeebleBrox
- 死亡杀手
- 费瓦达将军

相关实体
荷马·辛普森(Homer Simpson)与Sitcom“辛普森一家”有关。
显然,这是有关电视连续剧的信息,但是在“荷马·辛普森”查询的上下文中,“辛普森一家”的相关性得分(对于“辛普森一家”查询,相关性得分为16,200)。

使用知识图谱API 这里。
对于知识图条目的示例,该条目具有许多定义明确且清晰的相关实体,请查看 提字 (看起来是一种明确着手“知识”知识图的工具,并且做得很好)。
这些结果得分/相关性得分为“平均值”吗?
相关性分数可以被认为是置信度分数。对字符串确实指向指定实体的确信。
请务必注意,这些相关性得分并不代表Google搜索如何使用此数据构建SERP。
相关性得分“传统上”相当稳定
截至2019年夏季的典型相关分数
一般而言,较小的品牌商标得分在10分之内,对于较知名的品牌商标得分通常在1000至3,000分之间。
对于人们而言,这些分数往往更高。
在2019年7月之前,平均相关性得分变化很小。
上升幅度很小,很难在下图中看到-在1%到5%的范围内。
这是2019年夏季之前的平均值。

以下是一些针对个别品牌和个人的示例。
我们正在逐月查看1%,5%,甚至10%绝对最高值的变化。

可能会提高相关性得分
积极努力提高相关性得分似乎奏效。
在我积极工作的品牌上,随着我们添加更多佐证,得分趋于增加。
以数十或数百的平均分数,我设法实现的增幅是一个或两个百分点。从来没有什么过分的。
我的客户要求保持匿名。所以这里是一个名字被删除的。
我对确证的数量,位置和时机有很好的了解。
两年中的稳定增长对应于旨在增加在Crunchbase,Wikidata,行业站点等第三站点上的确证,并将品牌与知识图谱中的事件,C级员工,产品,合作伙伴相关联的积极工作(包括改进他们的相关性分数)。

分数可能下降
为什么分数会下降?
对于一个明确的名称,我猜想是为了保持知识图中的相关性,这里有一个新的佐证概念。
如果是这样,除非您的品牌自然产生新的第三方佐证,否则相关性得分将趋于下降。
这是一位在积极争取第三方佐证过程中失去信心的客户。
这显然很有趣,但绝对值得考虑。
我们可以将其等同于链接的构建(即获得第三方的佐证以加强自己在知识图中的地位,就像链接如何构建PageRank…,但还要考虑“新鲜度”方面)。
歧义度和相关性分数
拥有不明确的名字,例如我的名字或其他具有相同名字的实体(在本例中为Jason Barnard,足球运动员,播客,牙医,冰上曲棍球运动员,重力魔术师,棒球教练,碟形高尔夫球手……),获得或失去相关性/重要性/臭名昭著/提及会影响所有姓假的帮派成员的相关性得分。
因此,当名称/字符串不明确时要小心-那些起伏会受到其他具有相同名称以及您可能获得的佐证的实体的影响。

此外,明确的名称往往会比不明确的名称(明智地命名您的品牌)具有更高的相关性得分。 ?
令人兴奋的部分:2019年夏季=令人惊叹的知识图算法更新-布达佩斯
在2019年7月/ 8月,发生了两件事。
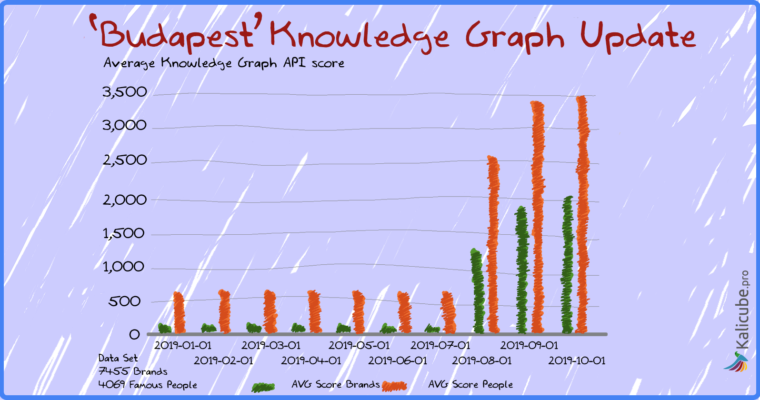
- 这些相关性分数疯狂。平均值达到顶峰(注意-我的数据集没有变化)。一些大的大赢家,一些小的赢家,但也有一些输家。
- 从Knowledge Graph API返回内容的实体数量增加了。
信心/相关分数
- 人员的相关性得分提高了五倍。
- 品牌的相关性得分提高了14倍。
- 品牌的相关性得分几乎是人们的3倍
- 品牌的平均相关度得分超过了人们。
- 在我看来,这是此更新中最重要的一点。现在,品牌已成为知识图表中的中心。

这些是很大的数字。
难以置信。
但是我已经检查,仔细检查并再次检查。
存在的实体大小/数量
这里的变化也很大。
在“知识图”中占一席位的品牌数量增加了42%以上。
7,504个品牌是一个非常随机的品牌。家喻户晓的名字广为流传,鲜为人知。因此,在我看来,这是一个重要的见解。
Google在“知识图”中有更多实体,或者至少对“查询字符串->实体”匹配更有信心。
对于人们而言,不幸的是数据存在偏差。
我一直跟踪的4,069个人中,大多数人都是著名的。
8月份仍然有明显的增长(确切地说,增长了3%),但是由于99%的命名实体已经返回了结果,因此我自己不会对此感到兴奋。
它确实提供了很好的支持证据,即知识图现在包含的实体比夏天之前多得多。
品牌退货的惊人增长确实表明知识图的大小显着增加。

我们多久能得到一次如此迅速而彻底地改变的数据集?
那有多激动?
相关性的关键因素:受欢迎程度,品牌知名度和新鲜度
流行度/概率(最终归结为概率)
看来,对实体的引用(以及与结果有关的潜在用户行为)已成为一个更为重要的因素。
在夏天之前看着“ Butch Cassidy”,历史人物的关联度最高。自更新以来,电影已接管。
我想这是因为在线参考文献的数量大得多,可能是最近/最新的嗡嗡声(并且可能是对历史搜索和点击数据的分析)。
在这里,我们可以看到此人在更新之前是最相关的,并且电影现在占据了主导地位。
新的和相关的引用,影响了用户的行为。
很有意思。
就个人而言,我无法解决这个问题。
有关信息,该人的相关性得分从535降低到330)。

品牌意识(又称荷马效应)
荷马·辛普森(Homer Simpson)与丹·卡斯特拉内塔(Dan Castellaneta)–相同“事物”的不同品牌知名度的极好例子(对不起,丹)。
荷马·辛普森(Homer Simpson)=极高的品牌知名度……相关性得分跃升了十倍。
丹·卡斯特拉内塔(Dan Castellaneta)(更广泛的公众不太了解的最直接相关的品牌)跃升了“仅”四倍。与演员相比,人物被引用频率更高,来源更多。
这是一个很好的比较,很好地表明了在知识图的这一迭代中,品牌知名度的重要性。

记住,相比之下,Dan落后了……这是非常重要的,但是这两个分数都发生了很大变化。
知识图只是切换了档位(也许是5档!)。
请考虑以下示例。
并非每个人都是赢家。
新鲜度/引用度
似乎新引用较少或引用增长不足的人和品牌也没有从此更新中受益。
看着已故的演员……那些“传奇人物” /“讽刺人物”的人会失地(得分下降)。
那些可能被认为是传奇人物的人大大超过了平均水平。
也许是因为传说经常被引用,并且永远保持“新鲜”(甚至在死亡60年后)。
在本次更新中,最近引用的数量和质量似乎非常重要。
 一点辩论
一点辩论
这是大型科技公司(对不起,我没有追踪亚马逊)。
他们都认为相关度得分高于平均水平。在我看来,这是合乎逻辑的。
对它们的引用是新鲜的,数量众多的,并且在某些技术公司倾向于“信任”的来源中。 ?也就是说,这里的规模令人难以置信。
Google击败了其余的人。
尽管Google似乎很在意自己,但合乎逻辑的是,他们的品牌名称应该会出现如此惊人的增长。
但是再看看数字。
Google增长了600倍。 Facebook的增长了500倍。苹果增长了460倍。
因此,实际上,微软是唯一没有取得太大进展的公司(如果您可以考虑将增长56倍,则表示“进展不大”)。

看来此更新是歪斜的,并给了科技公司过多的关注,特别是Google。
Google似乎是自己的知识图谱的焦点,这意味着内在的偏见。
如果您已连接到Google,则您的品牌将使Google的知识图更加容易浏览。
展望未来,内在的偏见往往会被夸大(因此将您的品牌附加到Google上并搭载)。
无论您从此洞察力中获得什么个人优势,这种偏见都会带来(尚未想象的)问题。我们拭目以待。 ?
如果还不够–刚刚发生另一次更新
知识图的“深度”已删除
我将Google认为与给定查询相关的平均结果数称为“深度”(覆盖实体,歧义度和相关实体)。
这只是一个很大的打击。
不知道这里发生了什么。然而。 ?

知识面板的存在被删除
我使用来自以下机构的数据跟踪了所有7,455个品牌和4,069位用户的SERP 权威。
10月,在我跟踪的数据集上,我看到一个知识面板的SERP数量下降了20%。
数据 AccuRanker 与我分享的涵盖英国范围更广的查询的内容显示,十月中旬知识面板的存在下降了13%。
值得思考的地方,但绝对是“持续的事情”。
两者有关系吗?
知识图的“深度”下降与知识面板的下降之间可能存在某种关系。
我将此新更新称为巴黎更新。并将进一步调查。
目前,布达佩斯更新让我感到非常震惊,这简直太难处理了。
附注:在我当时去过的城市后命名更新似乎是个好主意。
添加您的品牌并访问Kalicube.pro上的所有数据
请在我正在进行的品牌跟踪实验中添加品牌/个人品牌 这里。
添加您的品牌/您想知道的另一个品牌/您的名字/另一个超级人物的名字-越多越好。
图片积分
特色和后期图片:Kalicube.pro